- Learn
- Learn
Overview
Overview
AXIS Experience Architecture
In modern enterprises, customer and stakeholder outcomes must drive architecture, operations, and investment decisions. AXIS organizes this work into six guidance pillars that create a closed loop from intent to execution, grounded in leading standards such as TOGAF®, BizBOK® and OMG DMN/BPMN. Each pillar defines a focused domain of practice with clear outcomes, core artifacts, and skills, and together they form a mutually exclusive, collectively exhaustive experience architecture lifecycle.
On this site you will find:
- Short, web‑friendly chapters for each pillar
- MECE overview tables and lifecycle diagrams
- Pillar‑by‑pillar practice vignettes and metrics
- A three‑level master pathway and sample 12‑month rollout roadmap
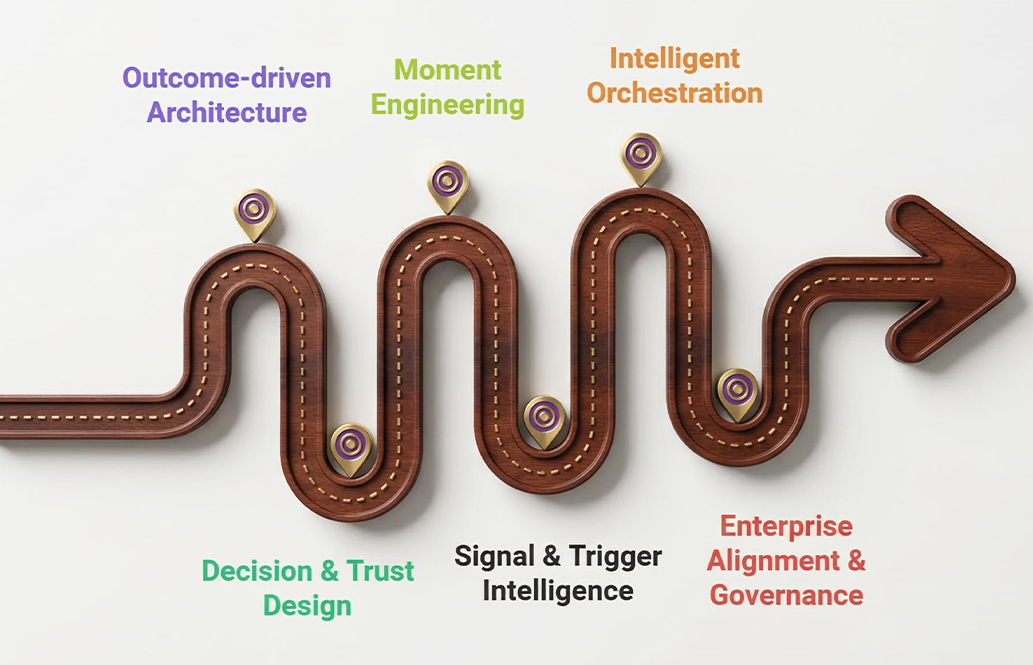
The Six AXIS Pillars
Outcome‑driven Architecture
Focus question
Why does the enterprise act? What value do people seek?
Signal & Trigger Intelligence
Focus question
What signals do we detect? When do we trigger?
The AXIS Feedback Loop
AXIS is designed as a continuous feedback loop rather than a one‑time methodology:
- Architecture → Decisions → Moments → Signals → Orchestration → Architecture
- Governance → Architecture → Decisions → Moments → Signals → Orchestration
This loop shows how outcome‑driven architecture and decision design shape the moments that matter, which generate signals. Signals then trigger orchestrated responses that, in turn, influence outcomes and feed back into architecture and governance.
Flow (conceptual):
- Define Outcomes → Model Decisions → Engineer Trust → Design Moments
- Detect Signals → Orchestrate Responses → Monitor & Govern → Define Outcomes (refine)
Monitoring and governance (Pillar 6) continuously refine outcomes, decision logic, and implementation patterns so the system adapts over time.
- Learn
Concept: What is Outcome‑driven Architecture?
Concept: What is Outcome‑driven Architecture?
Outcome‑driven architecture starts from what people are trying to achieve and uses that as the primary driver for design, investment, and change. Instead of beginning with systems, organizational charts, or processes, you begin with success states for stakeholders and treat everything else as a means to those ends.
A stakeholder outcome is a measurable end state that a person or group cares about (for example, “New customer completes first purchase within 10 minutes” rather than “Improve onboarding process”). In AXIS, Outcome‑driven Architecture connects four ideas in a straight line:
- Stakeholders – Who cares about this?
- Outcomes – What success looks like for them, in measurable terms.
- Value‑stream stages – How that success is delivered over time.
- Capabilities & initiatives – What the enterprise must be able to do, and what it funds and changes.
If you get this connection right, everything else in AXIS has a solid backbone:
- Pillar 2 models decisions that support outcomes.
- Pillar 3 designs moments where those outcomes are won or lost.
- Pillar 4 selects signals that show whether outcomes are on track.
- Pillar 5 orchestrates responses to protect or recover outcomes.
- Pillar 6 governs all of this against the outcomes the enterprise claims to care about.
Quick self‑check:
- Can you express your initiative’s purpose purely in terms of stakeholder outcomes, with no mention of systems or projects?
- For your top 5–10 capabilities, can you show which stakeholder outcomes each one enables and which outcomes would suffer if that capability degrades?
Why it matters
Outcome‑driven architecture is the antidote to tech or project‑driven change.
It:
- Reduces waste – Fewer features, projects, and migrations that nobody can tie back to specific outcomes.
- Improves alignment – Leaders, product, design, and delivery teams all anchor on the same “finish line” instead of on their own local goals.
- Enables governance – You can audit whether investments, roadmaps, and architectures still connect to the outcomes the organization says it prioritizes.
If you skip this pillar, later work on decisions (Pillar 2), moments (Pillar 3), and signals (Pillar 4) tends to optimize local details. You can have beautifully modeled decisions, elegant interactions, and rich telemetry that don’t actually move outcomes that matter.
How to learn and practice Pillar 1
Step A – Write clear outcome statements
Start small and concrete.
- Choose a scope: one product, service, or internal journey (for example, “customer onboarding,” “discharge process,” “incident response”).
- Identify one primary stakeholder: customer, patient, citizen, partner, or internal role (for example, “new customer,” “frontline nurse,” “on‑call engineer”).
- Draft 3–5 outcome statements using this pattern:
- “<Stakeholder> can <achieve result> within <time/conditions>.”
- Test each outcome:
- Is it an end state, not an activity? (“Onboarded and able to purchase” vs “Completed form.”)
- Would two independent people agree whether it happened if shown real data?
Practice prompt: Rewrite “Improve incident management” as an outcome for an on‑call engineer. (For example, “On‑call engineers can restore affected services within 30 minutes for 95% of P1 incidents.”)
Deliverable: A short list of 3–5 well‑formed outcomes for a single stakeholder.
Step B – Map outcomes to value streams
Turn each outcome into a journey.
For one outcome:
- Mark the trigger: What starts the journey? (for example, “customer clicks ‘sign up,’” “doctor enters discharge order,” “alert page is fired.”)
- List all stages from trigger to outcome achieved, in order.
- Name each stage from the stakeholder’s perspective (for example, “Provide details,” “Verify identity,” “Receive confirmation”), not the system’s (“API call,” “batch job”).
- For each stage, describe briefly:
- What the stakeholder is trying to do or feel.
- What the organization must do to enable that step.
You’re clarifying the flow of value toward the outcome.
Deliverable: A simple left‑to‑right value‑stream diagram (with all stages) for one outcome.
Step C – Identify enabling capabilities
Now identify what the enterprise must be able to do reliably at each stage.
Using your stages:
- For each stage, list 2–4 capabilities or competencies that must exist (for example, “identity verification,” “inventory visibility,” “bed assignment,” “real‑time alerting”).
- Merge duplicates and give each capability a clear, reusable name.
- Keep capability names technology‑agnostic:
- Good: “identity verification,” “payment settlement.”
- Weaker: “ID‑service‑01,” “PaymentDB cluster.”
Your goal is a vocabulary that business and technology can both understand and reuse.
Deliverable: A capability list, with each capability mapped to one or more value‑stream stages.
Step D – Build an outcome‑to‑capability matrix
Make traceability visible.
- Construct a basic matrix:
- Rows: stakeholder outcomes.
- Columns: capabilities.
- Mark where a capability is critical to achieving an outcome (for example, checkmark, dot, or heat level).
Use the matrix to:
- Spot high‑leverage capabilities serving many outcomes (often good candidates for extra investment, hardening, or standardization).
- Spot gaps where important outcomes depend on a surprisingly thin or fragile set of capabilities.
- Start a conversation about prioritization:
- Are we funding the capabilities that support the outcomes we claim to care about?
Deliverable: An outcome‑to‑capability matrix for at least one product or journey.
Step E – Define outcome measures
Anchor the outcomes in observable reality.
For each outcome, choose 3–5 measures, such as:
- Outcome attainment rate: percentage of cases where the outcome is reached (for example, new customers who complete onboarding and can transact).
- Time‑to‑outcome: median or P90 time from trigger to outcome (for example, time from “sign up started” to “first purchase”).
- Experience measure: a satisfaction or trust indicator at or after the outcome (for example, NPS after first purchase, discharge satisfaction rating).
- Business impact: revenue, cost, or risk tied to the outcome (for example, average revenue from customers who reach “first purchase,” reduction in readmissions after “timely discharge”).
Be explicit about:
- Data sources: where the measures come from.
- Cadence: how often they’re reviewed (for example, monthly, quarterly).
Deliverable: A small outcome measurement set for each outcome, with clear definitions and data sources.
- Learn
Concept: What is Decision & Trust Design?
Concept: What is Decision & Trust Design?
Decision & Trust Design starts from the outcomes and value streams you defined in Pillar 1 and focuses on the repeatable choices that materially affect those outcomes. Instead of letting policy and judgment stay hidden in code or tribal knowledge, you model who decides what, based on which information, under which rules, with which safeguards.
A decision is a repeatable choice that changes the path to an outcome (for example, “Approve claim,” “Route patient to fast‑track,” “Escalate incident to L3”). Decision & Trust Design connects:
- Outcomes and stages (from your Outcome Architecture Pack)
- Outcome‑critical decisions at those stages
- Inputs and sub‑decisions each decision depends on
- Business rules and automation boundaries
- Trust controls (logging, oversight, explainability, overrides)
When this chain is explicit, you can safely automate, audit, and improve decisions as conditions change.
Quick self‑check:
- For your main journey, can you name 5–10 decisions that truly change whether outcomes are reached?
- For one such decision, can you sketch its inputs, supporting decisions, and outputs in a way a non‑expert can understand?
Why it matters
Decision & Trust Design:
- Removes hidden policy: Rules stop living only in code and hallway conversations.
- Enables safe automation and AI: You know exactly what you’re automating and what must stay under human judgment.
- Builds trust: Stakeholders can see how decisions are made, challenge them, and rely on consistent behavior.
If you skip this pillar, you risk building powerful automation and analytics that amplify unclear or biased choices, and you make it hard to show regulators, customers, or leaders how critical decisions are being made.
How to learn and practice Pillar 2
Use your Outcome Architecture Pack as the starting point, especially the value‑stream diagram and outcome list.
Step A – Inventory outcome‑critical decisions
From each value‑stream stage:
- Ask: “What decision here significantly changes whether we achieve the outcome?”
- Capture decisions using a simple pattern:
- “Decide whether to <result> based on <inputs>.”
- Collect 10–20 decisions across the journey.
- Prioritize:
- Impact: Does this affect attainment of a key outcome?
- Frequency: How often is this decision made?
- Risk: What happens if it’s wrong (customer impact, safety, regulation)?
Deliverable: A decision inventory, with each decision mapped back to a stage and an outcome, and tagged with impact/frequency/risk.
Step B – Model the structure of a key decision
Pick one high‑priority decision from the inventory.
- Draw the main decision in the center (for example, “Approve claim?”).
- Surround it with:
- Input data (for example, policy details, claim amount, customer history).
- Supporting decisions (for example, “Check eligibility,” “Assess fraud risk,” “Verify documentation”).
- Connect inputs and supporting decisions to the main decision with arrows.
Check:
- Can someone unfamiliar with the domain see what information is needed and which sub‑decisions feed into the main one?
- Does every input and sub‑decision clearly link back to at least one outcome from Pillar 1?
Deliverable: A one‑page decision‑requirements diagram for one decision.
Step C – Turn policy into explicit rules
For the same decision (or a key supporting decision):
- Build a decision table:
- Columns for the most important input conditions (for example, amount ranges, risk scores, eligibility flags).
- One column for the decision result.
- Add 5–10 realistic rule rows that reflect how the organization currently behaves or wants to behave.
- Include a default/“otherwise” row for unexpected combinations.
Tie back to outcomes:
- For each rule row, note which outcome(s) it primarily supports (for example, “minimize fraud losses,” “maximize approval for low‑risk customers”).
Deliverable: A testable decision table for a real decision, with implicit policy made explicit.
Step D – Add a trust overlay
Now define how this decision earns and maintains trust.
For the same decision, specify:
- Logging:
- What gets recorded each time (inputs, rule hit, outcome, timestamp, decider identity).
- Oversight:
- Which cases must be manually reviewed (for example, large values, borderline scores, high‑risk segments).
- Who reviews them and in what timeframe.
- Explainability:
- What minimum explanation must be available (for example, “Declined because income below threshold and adverse history in last 6 months”).
- How explanations are presented to users or auditors.
- Overrides:
- Who is allowed to override the decision.
- How overrides are captured and later analyzed (for example, to refine rules or models).
Deliverable: A one‑page “trust overlay” document attached to the decision model.
Step E – Define and monitor decision quality
Choose 3–5 metrics for the decision:
- Decision latency: Time from request to decision.
- Quality/accuracy: Where you have later ground truth (for example, claim reopen rate, default rate).
- Override rate: Percentage of decisions overridden by humans (not necessarily “bad,” but a signal).
- Escalation rate: Volume sent for manual review.
- Stakeholder trust: Survey or feedback metric (for example, perceived fairness, clarity).
Connect back to outcomes:
- For each metric, identify which outcome(s) it influences (for example, “faster decisions improve Time‑to‑Outcome; unfair decisions harm trust and retention”).
Deliverable: A small decision‑quality metric set, with clear links to outcomes and data sources.
- Learn
Concept: What is Moment Engineering?
Concept: What is Moment Engineering?
Moment Engineering starts from the outcomes and journeys you mapped in Pillar 1 and the decisions from Pillar 2, and zooms into the specific interactions where those outcomes are won or lost. A moment is a focused segment of the journey with high emotional, cognitive, or risk weight where users decide to continue, abandon, or change their perception of you.
Examples:
- “Submit payment details”
- “Receive and understand discharge instructions”
- “Acknowledge a critical alert while on‑call”
Moment Engineering connects:
- Outcomes and value‑stream stages (Pillar 1)
- Decisions that happen at or around the moment (Pillar 2)
- Frontstage actions the stakeholder sees and performs
- Backstage support (systems, staff, processes)
- Fail points and recovery paths that protect the outcome
Quick self‑check:
- Can you point to 3–5 moments in your journey where a small design flaw causes outsized damage to outcome attainment or trust?
- For one moment, can you describe what the user sees, what is happening behind the scenes, and what happens if things go wrong?
Why it matters
Moment Engineering:
- Concentrates effort where it counts – on interactions that drive completion, satisfaction, and trust.
- Bridges UX and architecture – tying user experience directly to capabilities, decisions, and outcomes.
- Improves resilience – because fail points and recovery paths are designed, not improvised.
If you skip this pillar, you may improve processes and systems in general but still lose users at a few fragile, high‑impact points.
How to learn and practice Pillar 3
Use your Outcome Architecture Pack (stages) and Decision inventory to anchor where moments occur.
Step A – Identify moments of truth
For a given journey:
- Walk the value‑stream stages and decision points.
- Mark steps where:
- A key decision is made (by the user or the system).
- Users often drop off, complain, or seek help.
- Emotion is high (anxiety, relief, frustration, delight).
- Capture 5–10 candidate moments, then select the top 3–5 based on:
- Impact on outcome attainment.
- Impact on trust and perception.
- Volume (how often it occurs).
Deliverable: A moment inventory with priority ratings.
Step B – Create a moment blueprint slice
Pick one high‑priority moment.
- Create three horizontal lanes:
- Customer actions: clicks, choices, conversations at and around the moment.
- Frontstage: what is visible to them (UI, staff, messages, channels).
- Backstage: internal tasks and systems supporting the moment (queues, APIs, handoffs).
- Map a small time window:
- A few steps before the moment (setup).
- The moment itself (the “peak” interaction).
- A few steps after (confirmation, follow‑through).
- Note where decisions from Pillar 2 are executed in the flow.
Deliverable: A one‑page moment blueprint slice with frontstage/backstage lanes.
Step C – Identify fail points and design recovery
On the blueprint:
- Circle fail points, such as:
- Errors, timeouts, confusing messages, missing information.
- Internal delays or misrouted work.
- For each fail point, define:
- Prevention: one design change that makes the failure less likely (for example, clearer instructions, progressive data capture, validation).
- Recovery: what happens if it still fails, both internally and visibly to the user (for example, clear error messages, retry options, alternative channels, callbacks).
Connect to outcomes:
- For each fail point, note which outcome or metric it threatens (for example, “this failure harms Time‑to‑Outcome and satisfaction”).
Deliverable: A fail‑point and recovery plan layered onto the moment blueprint.
Step D – Define moment‑level metrics
For the same moment, choose 3–5 measures:
- Moment success rate: percentage of users who complete the interaction successfully.
- Drop‑off rate: percentage who abandon at that step.
- Time‑on‑moment: how long it takes from start to finish of that interaction.
- Error rate: failures per 100 or 1 000 attempts (for example, validation errors, retries).
- Experience metric: satisfaction or confidence captured at or right after the moment (for example, a 1–5 rating).
Tie back to outcomes:
- Make explicit which outcome(s) each metric primarily supports.
Deliverable: A concise KPI set for the moment, with baseline values once measured.
Step E – Run a moment‑focused improvement experiment
For one moment:
- Formulate a simple hypothesis:
- “If we <change>, then <metric> will improve by <X> because <reason>.”
- Choose one or two low‑risk design changes:
- Form layout, copy, sequencing, confirmation patterns, error handling.
- Run an experiment:
- A/B test if possible, or a before/after comparison over a defined period.
- Measure the impact on moment‑level metrics and relevant outcomes.
Deliverable: A one‑page “moment experiment” summary: baseline, change, results, next actions.
- Learn
Concept: What is Signal & Trigger Intelligence?
Concept: What is Signal & Trigger Intelligence?
Signal & Trigger Intelligence takes the outcomes, stages, decisions, and moments from Pillars 1–3 and decides what to watch and when to act. Instead of gathering all possible data, you curate signals (data points that should change behavior)and define triggers (the conditions under which those signals cause actions).
Key notions:
- Data: raw observations.
- Signal: a piece of data you have explicitly decided is meaningful for an outcome.
- Trigger: a rule mapping signal patterns to actions (for example, alerting, starting workflows, throttling, or notifying stakeholders).
This pillar connects:
- Outcomes and moments (what matters).
- Signals that indicate health, risk, or opportunity.
- Event schemas and standards for those signals.
- Trigger rules that turn observation into action.
- Detection quality metrics that tell you how well your “senses” work.
Quick self‑check:
- For one outcome and one critical moment, can you list 5–10 signals that genuinely change how you’d respond?
- Can you state, for at least one signal, the exact condition that should trigger action and what that action is?
Why it matters
Signal & Trigger Intelligence:
- Sharpens focus: You track fewer but higher‑value signals that directly relate to outcomes and moments.
- Improves responsiveness: Important changes are noticed and acted upon quickly and consistently.
- Supports learning: Signals become the feedback loop for improving processes, decisions, and moments.
If you skip this pillar, you get noisy dashboards and alert fatigue, or you miss critical shifts in user behavior and system health until it’s too late.
How to learn and practice Pillar 2
Base your work on:
- Outcome measures (Pillar 1).
- Decision quality metrics (Pillar 2).
- Moment metrics (Pillar 3).
Step A – Identify meaningful signals
For one journey and outcome:
- Look at your value stream, decisions, and critical moments.
- Ask:
- What events show that we are on track to an outcome?
- What events show we are off track or about to be?
- What events show an opportunity to improve or upsell?
- List 10–15 candidate signals and tag each as:
- Health (for example, OutcomeAchieved, SLO met).
- Risk (for example, repeated errors, high latency, abandonments).
- Opportunity (for example, high engagement, new need detected).
Deliverable: A signal inventory aligned to outcomes, decisions, and moments.
Step B – Define event schemas
For 3–5 high‑priority signals:
- Name each signal clearly and write a one‑sentence purpose.
- Define:
- Required fields (for example, IDs, timestamps, outcome identifiers, context).
- Optional fields (for example, experiment variant, device type, channel).
- A version field and basic rules for evolving the schema safely.
Ensure:
- Each schema makes it easy to tie the signal back to the outcome, decision, or moment it relates to.
- Fields are namespaced and typed clearly enough for implementation and analytics.
Deliverable: A short event catalog describing key signals and their schemas.
Step C – Design trigger rules and actions
For each key signal:
- Define trigger conditions:
- Simple conditions (for example, “error rate > 2% over 5 minutes”).
- Patterns (for example, “3 failed logins in 2 minutes from same account”).
- Combinations (for example, “checkout abandonment spike + concurrent latency increase”).
- Map each condition to a concrete action:
- Notify: who, via what channel, with what summary.
- Start a workflow: which orchestrated response (Pillar 5).
- Log only: for low‑risk signals used for analysis but not immediate action.
Think at two levels:
- Individual‑level triggers (per user, transaction, device).
- Aggregate‑level triggers (trend or spike across many users or systems).
Deliverable: A trigger matrix: signals → conditions → actions.
Step D – Define detection quality metrics
To understand how well your signals and triggers work, select 3–5 metrics such as:
- Detection latency: Time from event occurrence to trigger/action.
- Mean time to detect (MTTD): For high‑severity issues.
- False positive rate: Percentage of alerts or triggers that do not correspond to real issues.
- Coverage: Percentage of critical outcomes/moments with at least one meaningful signal and trigger.
- Schema compliance: Percentage of events that conform to the defined schema.
Tie these metrics back to outcomes:
- For example, better detection latency and coverage should reduce Time‑to‑Outcome and improve reliability metrics.
Deliverable: A detection scorecard for your chosen journey.
Step E – Tune and prune signals
Select one domain (for example, checkout, claims, on‑call) and:
- Inventory existing metrics and alerts.
- Tag each as:
- Health, risk, or opportunity, or “noise” if not clearly tied to an outcome.
- Decide:
- Which signals to decommission or downgrade.
- Which high‑value signals need better triggers or better schemas.
- Re‑measure your detection metrics after changes.
Deliverable: A short “signal tuning” before/after summary (for example, number of alerts reduced, coverage improved, false positives reduced).
- Learn
Concept: What is Intelligent Orchestration?
Concept: What is Intelligent Orchestration?
Intelligent Orchestration takes the triggers from Pillar 4 and defines how the enterprise responds, end‑to‑end, across systems and teams, including how it recovers when things go wrong. It is the designed choreography that turns “We saw something important” into “We handled it in a reliable, outcome‑aligned way.”
It connects:
- Triggers and signals (Pillar 4)
- Activities across capabilities (Pillar 1)
- Decisions that must be taken during the response (Pillar 2)
- Moments where users experience the response (Pillar 3)
- Reliability objectives and policies that keep the whole flow safe
Quick self‑check:
- For a high‑impact trigger (for example, fraud risk, SLO breach, critical incident), can you describe the ideal step‑by‑step response, including who/what acts at each step?
- If a mid‑flow step fails, do you know which earlier actions must be compensated, and what the user experiences?
Why it matters
Intelligent Orchestration:
- Keeps promises: It ensures your response flows actually deliver the outcomes and SLOs you commit to.
- Reduces chaos: Failures and edge cases are handled via known, tested patterns, not improvised on the fly.
- Makes improvement possible: Because response flows are explicit and instrumented, you can refine them over time.
If you skip this pillar, triggers may fire, but responses are manual, inconsistent, and opaque, increasing risk and eroding trust.
How to learn and practice Pillar 2
Base your work on:
- Outcome Architecture Pack (which capabilities and stages matter most).
- Signals and triggers (Pillar 4).
- Decision & Trust models (Pillar 2).
Step A – Select a high‑impact response scenario
Choose a trigger from Pillar 4, such as:
- “High fraud risk detected for a transaction.”
- “Critical SLO breach for a core service.”
- “High‑value customer abandons checkout at payment step.”
For that trigger:
- Define the start event precisely (which signal and condition).
- Define the desired end state (for example, “risk assessed and transaction either safely completed or reversed,” “service restored and cause mitigated”).
- List key constraints:
- Time (for example, must respond within X minutes).
- Regulatory (for example, audit trail, approvals).
- Experience (for example, minimize disruption to user).
Deliverable: A concise scenario description (start, desired end, constraints).
Step B – Draw the response workflow
For the chosen scenario:
- Sketch a workflow with:
- Start event (trigger).
- 5–15 activities:
- Automated actions (for example, checks, updates).
- Human tasks (for example, review, approval, outreach).
- Branching logic (for example, thresholds, decision points).
- End states (for example, resolved, escalated, failed gracefully).
- For each activity, note:
- Which capability (from Pillar 1) is used.
- Which team or system is responsible.
Connect to Pillar 2:
- Highlight where outcome‑critical decisions occur in the flow.
Deliverable: A one‑page orchestration workflow diagram for one scenario.
Step C – Design compensating actions and fallbacks
On the workflow:
- Identify steps that change external state (for example, charging a card, shipping goods, sending an official notification).
- For each, define a compensating action if a later step fails (for example, issue refund, cancel shipment, send correction).
- Specify:
- Who/what performs the compensation.
- Under what conditions it is triggered.
- Also define fallback paths when the primary approach is unavailable (for example, manual processing, alternative provider, degraded mode).
Tie back to outcomes and trust:
- Which outcomes are protected by each compensation/fallback?
Deliverable: A compensation and fallback list, mapped to workflow steps.
Step D – Set SLOs and operational policies
For the orchestrated scenario:
- Define 1–2 user‑visible SLOs (Service Level Objectives), such as:
- “95% of fraud reviews completed within 15 minutes.”
- “99.9% of login attempts succeed per month.”
- Define the SLIs (Service Level Indicators) that measure them.
- Connect to Pillar 4:
- Which signals feed those SLIs?
- Define operational policies, such as:
- When to alert (for example, error budget nearly used).
- Who is on the hook for response.
- When to pause risky changes (for example, code freezes, feature flags).
Deliverable: An SLO/SLI and policy sheet for the scenario.
Step E – Exercise and refine the orchestration
To make the orchestration real:
- Run tabletop exercises or simulations:
- Walk through the workflow step by step for normal and failure cases.
- Check that roles, decisions, and handoffs are clear and realistic.
- Gather issues and opportunities:
- Missing steps or owners.
- Unrealistic time expectations.
- Over‑complicated branches.
- Update:
- Workflow diagram.
- Compensations.
- SLOs and policies.
Tie back to Pillar 1:
- Validate that the scenario still advances the outcomes and metrics you care about most.
Deliverable: A short “orchestration test” summary and updated design.
- Learn
Concept: What is Enterprise Alignment & Governance?
Concept: What is Enterprise Alignment & Governance?
Enterprise Alignment & Governance makes AXIS a durable capability by defining why it exists, who owns what, how “good” is defined, and how progress is measured. It ensures that the work from Pillars 1–5 is not just a one‑off exercise but an ongoing part of how the organization operates and makes decisions.
It connects:
- Strategy and outcomes (why we care).
- Roles and decision rights for each pillar and artifact.
- Standards and checklists that keep work consistent and lightweight.
- Metrics and review cycles that show whether AXIS is being used and is valuable.
Quick self‑check:
- Can you show a one‑page AXIS charter that explains its purpose, scope, and principles for your organization?
- For each of the five other pillars, can you name who is accountable, who contributes, and how their work is reviewed?
Why it matters
Enterprise Alignment & Governance:
- Makes AXIS sustainable: It outlives individual projects, reorganizations, and champions.
- Clarifies ownership: People know who is responsible for outcomes, decisions, moments, signals, and orchestration.
- Enables assurance: You can demonstrate to boards, regulators, and partners that experience architecture is being managed deliberately.
If you skip this pillar, AXIS is at risk of becoming “that thing we did last year,” with practices slowly drifting, duplicating, or being overwritten by other frameworks.
How to learn and practice Pillar 2
Build on all prior artifacts:
- Outcome Architecture Packs.
- Decision & Trust Packs.
- Moment, Signal/Trigger, and Orchestration Packs.
Step A – Draft an AXIS charter
Create a one‑page charter that covers:
- Purpose: Why AXIS is being adopted (for example, “to align architecture and operations with stakeholder outcomes and trust”).
- Scope: Where it applies (for example, specific portfolios, value streams, business units).
- Principles: 5–7 guiding principles (for example, outcome‑first, transparency, proportional governance, evidence‑based changes).
- Key decision domains: What decisions AXIS governance owns or strongly influences (for example, approving outcome maps, reference patterns, SLO frameworks).
Deliverable: A charter suitable for executive endorsement and publication.
Step B – Define roles and decision rights (RACI)
For each pillar and major artifact type (Outcome Architecture Pack, Decision & Trust Pack, etc.):
- Identify:
- Accountable role (one role ultimately responsible).
- Responsible roles (who does the work).
- Consulted roles (who must be involved).
- Informed roles (who needs updates).
- For key governance decisions (for example, “approve new outcomes,” “approve SLOs,” “approve governance standards”), define:
- Who decides.
- Who must be consulted.
- Escalation paths.
Capture all of this in a simple RACI table.
Deliverable: A RACI covering pillars, core artifacts, and key governance decisions.
Step C – Create minimum standards and checklists
For each core AXIS artifact:
- Outcome Architecture Pack
- Decision & Trust Pack
- Moment Blueprint Pack
- Signal & Trigger Pack
- Orchestration Pack
Define 5–10 minimum standards per pack. For example:
- Outcome pack: “All outcomes are measurable and have at least one metric; capabilities are tech‑agnostic; traceability matrix has no orphan initiatives.”
- Decision pack: “Every modeled decision has a trust overlay; decision tables have at least one test scenario.”
- Signal pack: “Every trigger is owned; no critical outcome lacks at least one meaningful signal.”
- Orchestration pack: “Each scenario has compensations defined for critical state changes; SLOs and SLIs are documented.”
Convert these into short, checklist‑style templates teams and reviewers can use.
Deliverable: A set of AXIS minimum‑standards checklists.
Step D – Define governance metrics and cadence
Agree on 5–8 governance KPIs, such as:
- Coverage:
- Percentage of key value streams with Outcome Architecture Packs.
- Percentage of outcome‑critical decisions with Decision & Trust Packs.
- Percentage of critical flows with Signal & Trigger and Orchestration Packs.
- Quality:
- Percentage of packs meeting minimum standards at review.
- Number and severity of audit/review findings per period.
- Adoption:
- Training and certification coverage (Foundation, Practitioner, Architect).
- Participation in AXIS reviews and communities of practice.
Define:
- Data sources for each metric.
- How often they are reviewed (for example, quarterly review).
- Who owns each metric.
Deliverable: A governance scorecard design (metrics, owners, cadence).
Step E – Run and refine a pilot governance cycle
Pick one portfolio, product line, or unit.
- Apply:
- The charter (make it explicit for that context).
- The RACI (assign names, not just roles).
- The minimum standards (used in a review of a real initiative).
- The scorecard (measure at least once).
- Run a pilot governance review:
- Use the checklists to review a real set of AXIS artifacts.
- Capture where governance added clarity and where it felt like unnecessary friction.
- Refine:
- Simplify or strengthen checklists based on feedback.
- Adjust RACI if there are ownership gaps or overlaps.
- Update charter wording if needed.
Deliverable: A short “governance pilot” summary and refined governance assets.
- Learn
Operating Model
The operating model pattern embeds “moment ownership” and decision rights into organizational design, funding, and governance so AXIS outcomes are accountable, measurable, and continuously improved rather than treated as informal cross-team collaboration.
Why it matters for AXIS
AXIS treats moments as owned promises. Without an operating model, “moment design” becomes a workshop artifact with no enduring accountability. The Business Architecture Guild defines an operating model as an abstract representation of how an organization operates across domains to accomplish its function, which is precisely the layer where ownership, decision rights, and cross-domain coordination must be codified.
Embedding moment ownership and decision rights
AXIS ownership rule
Each moment must have a single accountable “Moment Owner” (business outcome accountability), plus explicit technical and data stewardship counterparts (implementation accountability). This mirrors the event-driven division of responsibilities where producers own schema/semantics and consumers own effect semantics.
Decision rights (minimum set)
- Moment promise changes (what the enterprise is committing to deliver).
- Policy constraints (privacy, safety, compliance).
- Orchestration boundary decisions and SLA commitments.
- Contract changes for trigger/signal events and telemetry definitions.
Funding and portfolio alignment
AXIS moments should be fundable units of value realization capacity, not project tasks. Lean Portfolio Management in SAFe explicitly defines LPM as aligning strategy and execution through strategy and investment funding, agile portfolio operations, and governance, and positions portfolios as sets of development value streams that support operational value streams for customers. Map “moments” onto this structure as outcome commitments tied to value streams and funded accordingly.
RACI examples
These are reference RACI patterns (adapt per enterprise structure; unspecified):
RACI for a moment (experience outcome)
- Accountable: Moment Owner (business leader responsible for the promise and KPIs), Business architect (Documentation, architecture enablement)
- Responsible: Product/Value Stream Lead (delivery and iteration), Orchestration Architect (boundary + failure design), Data Steward (signal definitions).
- Consulted: Security/Privacy, Architecture Board, Customer Ops, Platform Team.
- Informed: Downstream domain teams impacted by contract changes.
RACI for an event contract
- Accountable: Producer Domain Owner (semantic owner).
- Responsible: Process Architect (discovery, documentation, architecture enablement), Producer engineering team (schema + change management), Platform governance (broker policy), Observability lead (correlation standards).
- Consulted: Key consuming domains, architecture governance, privacy.
- Informed: All registered consumers through contract registry publication.
Competency requirements
Competencies are framed as cross-domain because AXIS moments traverse domains:
- Business architecture literacy: value streams, stages, customer value delivery/proposition, stakeholder roles, operating model interpretation.
- Event and contract discipline: schema/semantics ownership and change management.
- Observability engineering: distributed tracing and messaging semantic conventions.
- Governance execution: compliance reviews, SLAs/OLAs, monitoring/reporting, dispensations.
- Privacy and security risk management.
Change management steps
A pragmatic change sequence that aligns operating model shifts with governance controls:
- Stand up a “moment portfolio” with owners and a minimal KPI set per moment.
- Establish contract governance gates: publish event contracts and enforce compatibility rules in delivery pipelines.
- Standardize observability: adopt OpenTelemetry context propagation and messaging conventions across producers/consumers.
- Institutionalize governance cadence: compliance reviews for major moments and major contract changes, plus monitored SLAs and exception handling.
- Expand funding alignment: treat high-impact moments as funded initiatives within portfolio governance, consistent with LPM’s investment funding and governance model.
Anti-patterns
Five operating model anti-patterns that prevent AXIS from becoming an operating discipline:
- Everyone owns the moment: diffuse accountability, no single accountable owner, producing inconsistent outcomes and endless prioritization conflict. This directly violates the notion of governance as owned responsibilities ensuring integrity and effectiveness.
- Funding only features, not outcomes: portfolio decisions ignore moment reliability as an investment unit, despite LPM framing that aligns strategy and execution through funding and governance.
- No producer contract accountability: treating schema changes as “implementation detail” instead of the primary coupling contract, contradicting guidance that producers own schema/semantics and change management.
- Governance only at design time: no runtime monitoring and reporting against SLAs/OLAs, despite governance frameworks explicitly including these as key elements.
- Privacy bolted on after observability: extensive logging without minimization and purpose controls, conflicting with minimization principles and the reality that context and baggage propagate widely.
Five-step implementation checklist
- Assign moment owners: one accountable owner per moment, published in a moment portfolio registry.
- Establish decision rights: define who can change moment promise, orchestration boundary, event contracts, and SLAs.
- Align funding: create portfolio-level allocation for top moments, consistent with investment funding and governance orientation.
- Implement governance cadence: compliance reviews for major changes, plus monitoring/reporting routines tied to SLAs.
- Build competency and enablement: train producers/consumers on contract discipline, tracing propagation, and privacy guardrails.
AXIS Experience Architecture
In modern enterprises, customer and stakeholder outcomes must drive architecture, operations, and investment decisions. AXIS organizes this work into six guidance pillars that create a closed loop from intent to execution, grounded in leading standards such as TOGAF®, BizBOK® and OMG DMN/BPMN. Each pillar defines a focused domain of practice with clear outcomes, core artifacts, and skills, and together they form a mutually exclusive, collectively exhaustive experience architecture lifecycle.
On this site you will find:
- Short, web‑friendly chapters for each pillar
- MECE overview tables and lifecycle diagrams
- Pillar‑by‑pillar practice vignettes and metrics
- A three‑level master pathway and sample 12‑month rollout roadmap
The Six AXIS Pillars
Outcome‑driven Architecture
Focus question
Why does the enterprise act? What value do people seek?
Signal & Trigger Intelligence
Focus question
What signals do we detect? When do we trigger?
The AXIS Feedback Loop
AXIS is designed as a continuous feedback loop rather than a one‑time methodology:
- Architecture → Decisions → Moments → Signals → Orchestration → Architecture
- Governance → Architecture → Decisions → Moments → Signals → Orchestration
This loop shows how outcome‑driven architecture and decision design shape the moments that matter, which generate signals. Signals then trigger orchestrated responses that, in turn, influence outcomes and feed back into architecture and governance.
Flow (conceptual):
- Define Outcomes → Model Decisions → Engineer Trust → Design Moments
- Detect Signals → Orchestrate Responses → Monitor & Govern → Define Outcomes (refine)
Monitoring and governance (Pillar 6) continuously refine outcomes, decision logic, and implementation patterns so the system adapts over time.


